What's Next?
Bytecode is something that modern programmers rarely have to touch. The rare few that do typically get at least an assembler up and running as soon as possible. Bytecode is rarely practical, and horrible for maintenance and readability.
Even the most basic of assemblers hold a few critical
advantages. With bytecode, the code you write
has to conform to fixed positions. If you want to jump
to a point in code, or access a place in memory, that
position must be hardcoded. On top of that, assembly
uses mnemonics that are far easier to remember and quickly
interpret. rather than needing a instruction table,
most assembly instructions are intuitive. ADD A B
is far easier to read and manage mentally than a block containing the number 11.
Comments are also quite useful. With bytecode, there's only space for code and data, as everything you write could be executed by the processor. With assembly, you can select lines or parts of lines to ignore, and use that space to store information to clarify program specifics to the reader.
Bytecode maintains one advantage. Self-modification. A clever programmer writing bytecode can take make use of far more than the apparant usable space by storing new instructions on top of the old ones, and then re-executing the block.
Unfortunately, it does have a few drawbacks. While it's nice for space-saving, it's not great for the modern processor's caching systems. When you modify the code at runtime, the processor's cached bytecode becomes invalid, and it has to stop and pull in the new code. Additionally, it's not great for system security. If the program can modify itself, the user may be able to coerce the program to make malicious self-modifications, jumping into blocks of code that the program wasn't intended to run.
Manual Bytecode Generation
Written in bytecode manually, I had to first write the program out on paper, and then translate the chunks into operations by consulting the instruction table. This was slow to write, and annoying to debug.
Bytecode Program
- writing requires complex mental model
- separation of code and output unclear
- reading requires lookup table for ops

Automatic Bytecode Generation
Taking far less time to write, this was written in assembly and then assembled using an assembler. The resulting program performs the same operations in the same period of time, and the source is readable, and far more easily modified. As an added legibility bonus, logical errors are far easier to spot.
Assembly Program
- requires knowledge of asm
- fewer hardcoded positions
- lots of space for comments
; INIT
start:
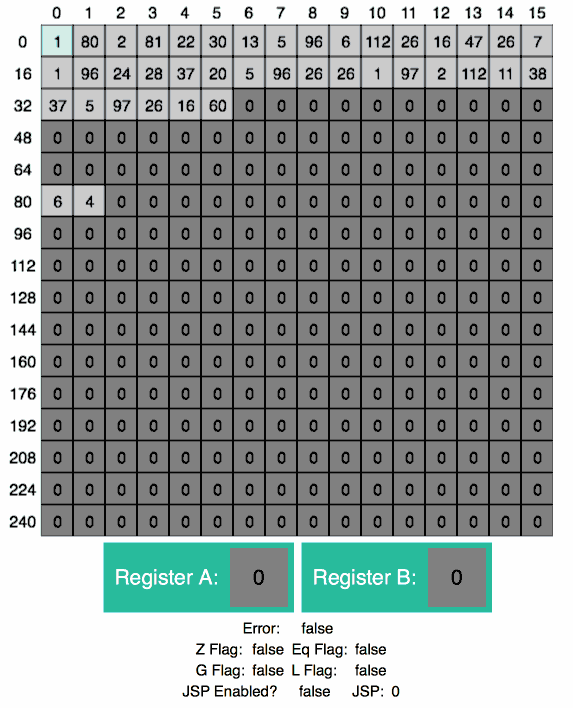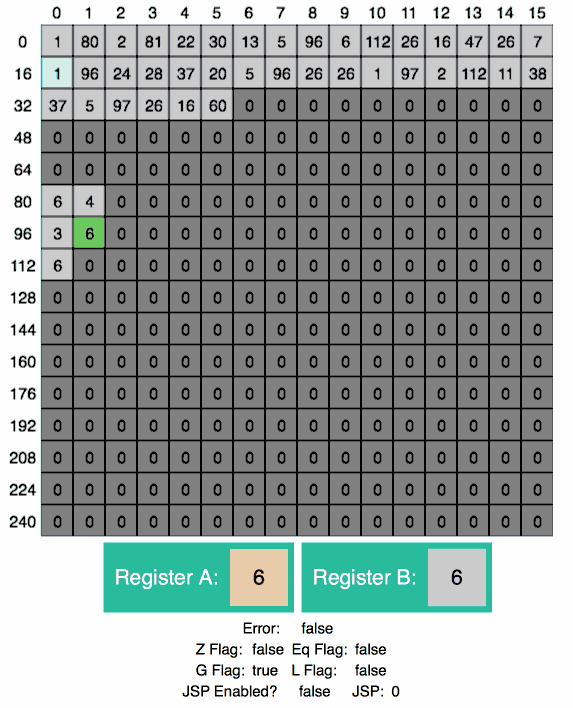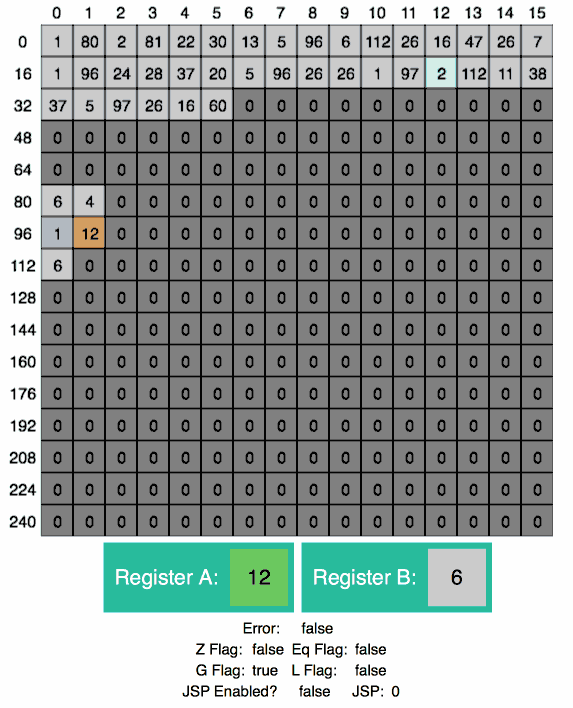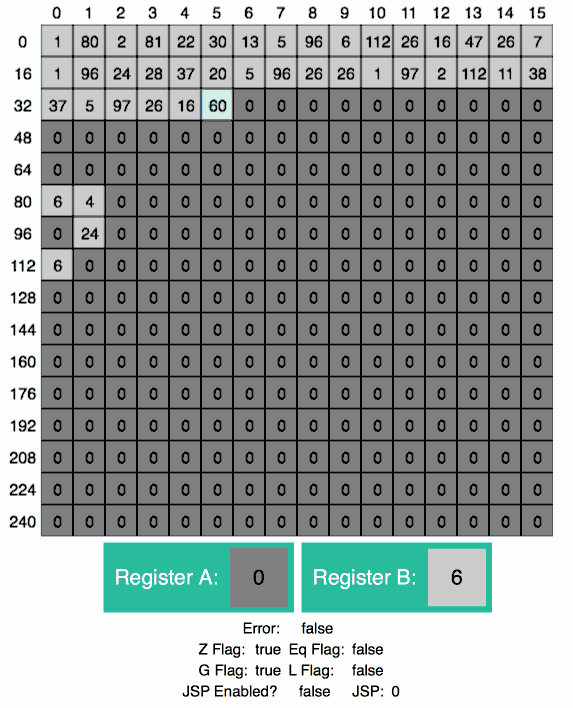
LOAD A 80 ; load x
LOAD B 81 ; load y
CMP A B ; is x > y?
JG swap ; goto swap
; 9 - SAVE_VAR
save_var:
STORE A 96 ; save min(x, y) as i
STORE B 112 ; save max(x, y) as increment
JMP loop
; 32 - SWAP
swap:
SWAP A B ; (x, y) -> (y, x)
JMP save_var
; 36 - LOOP
loop:
LOAD A 96 ; get i
ISZERO A ; is i == 0?
JZ exit
DEC A ; i--
STORE A 96 ; save new i
JMP add_increment
; 67 - ADD INCREMENT
add_increment:
LOAD A 97 ; read in cumulative value
LOAD B 112 ; read in increment
ADD A B ; cumulative = cumulative + increment
JERR exit ; if overflow, exit
STORE A 97 ; save new cumulative
JMP loop
; 255 - EXIT
exit:
HALT
; DATA
$80 6 4 ; x, yAssembled Program
- final program more compact
- visual code block distinction is harder
- no ability to add annotation